
Широкое использование систем переработки информации в различных сферах управленческой деятельности, для решения сложных экономических задач, проведения научных исследований обусловливают повышенные требования к эффективности организации данных в условиях коллективного пользования.
Традиционный способ организации данных в виде массивов, ориентированных на конкретные задачи, отличается статичностью, жесткой привязкой к соответствующему программному обеспечению, приводит к дублированию при накоплении и проверке данных, вызывает значительный перерасход памяти на их хранение, частую реорганизацию данных при изменении задач и т.п.
Одним из главных путей преодоления указанных недостатков является создание баз данных, обеспечивающих поддержание в системе динамической информационной модели сложных управляемых объектов и процессов и коллективный доступ к ней.
1. Организация баз данных
База данных (БД) определяется как совокупность взаимосвязанных данных, характеризующихся: возможностью использования для большого количества приложений; возможностью быстрого получения и модификации необходимой информации; минимальной избыточностью информации; независимостью прикладных программ; общим управляемым способом поиска.
Возможность использования базы данных для многих прикладных программ пользователя упрощает реализацию комплексных запросов, снижает избыточность и повышает эффективность использования информации в системах обработки данных. Минимальная избыточность и возможность быстрой модификации позволяют поддерживать данные на одинаковом уровне обновления. Независимость данных и использующих их прикладных программ является основным свойством базы данных. Независимость данных подразумевает, что изменение данных не приводит к изменению прикладных программ.
Традиционной формой организации баз данных, обеспечивающей такую независимость, является трехуровневая структура: логическая структура данных прикладного программиста (подсхема); общая логическая, структура данных (схема); физическая структура данных.
Схемы и подсхемы базы данных часто изображают в виде диаграмм. На рис. 1 приведена общая схема логической структуры базы данных и подсхемы двух прикладных программистов, которые имеют различные представления о данных. Сплошные линии обозначают связи на схеме. Простые связи обозначаются одной стрелкой, связи «один ко многим» — двойной стрелкой. Штриховые линии отображают перекрестные ссылки. Наличие перекрестных ссылок позволяет избежать повторения записей ПОСТАВЩИК и СПЕЦИФИКАЦИИ — ПАРТИИ -ТОВАРА в каждой записи СТАТЬЯ ЗАКУПКИ.
Объектно-ориентированные базы данных. _Объектно-ориентированные_БД. ...
... Объектно-ориентированные базы данных. Объектно-ориентированные базы данных представляют информацию, которая в них содержится в виде объектов, которые хранятся в памяти, как и в объектно-ориентированных языках программирования, таких как С++ и Java. Объектно-ориентированные системы управления базами данных ...
Создание базы данных не является единовременным процессом, оно растягивается на весь период ее существования. Трехуровневая организация обеспечивает возможность быстрого изменения структуры базы данных в условиях ведения и модификации систем управления и наращивания задач пользователей, а также в условиях совершенствования и наращивания аппаратных средств. Трехуровневая организация обеспечивает взаимную независимость изменений общей логической структуры базы данных и прикладных программ (логическая независимость данных) и возможность изменения физического расположения и организации данных без изменения общей логической структуры данных и структур данных прикладных программистов (физическая независимость).
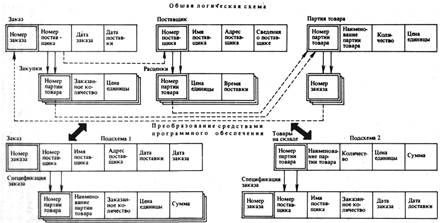
Рис. 1
2. Системы управления базами данных
Использование систем управления базами данных (СУБД) позволяет исключить из прикладных программ описание данных и детальное программирование управления данными. Описания заменяются ссылками на общую логическую структуру данных, а программирование управления – командами манипулирования данными, которые выполняет универсальное программное обеспечение.
Основной функцией СУБД наряду с обновлением данных является обработка запросов пользователей по поиску и передаче данных прикладным программам. Например, последовательность основных действий, реализуемых СУБД в процессе считывания записи, состоит из следующих операций: прикладная программа выдает запрос СУБД на чтение записи, в котором содержится значение ключа сегмента или записи; СУБД осуществляет в подсхеме прикладной программы поиск описания данных, на которые выдан запрос; СУБД с помощью общей логической схемы данных определяет, какого типа логические данные необходимы; СУБД по описанию физической организации данных определяет, какую физическую запись требуется считать; СУБД выдает операционной системе команду чтения требуемой записи; операционная система считывает данные в системные буферы; СУБД на основании сравнения схемы и подсхемы выделяет информацию, запрошенную прикладной программой; СУБД передает данные из системных буферов в рабочую область прикладной программы.
Действия, которые осуществляет СУБД при обновлении данных, аналогичны операциям считывания. СУБД будет осуществлять необходимые преобразования данных в системных буферах, обратные тем преобразованиям, которые были сделаны при считывании данных. Затем система управления базами данных выдает операционной системе команду ЗАПИСАТЬ. Общая архитектура системы управления базами данных приведена на рис. 2. Она присуща всем СУБД, которые различаются ограничениями и возможностями по выполнению соответствующих функций.
Процесс сравнения и выбора таких систем для конкретного применения сводится к сопоставлению их возможностей с конкретными требованиями и ограничениями пользователя.
Для работы с системой управления базой данных необходимо несколько языков: языки программирования, языки описания схем и подсхем, языки описания физических данных. Прикладной программист использует языки программирования для написания программ (КОБОЛ, ФОРТРАН, ПЛ/1, АССЕМБЛЕР) и средства для описания данных — язык описания подсхем. Язык описания подсхем может представлять собой средство описания данных в языке программирования, средство, обеспечиваемое СУБД, а также независимый язык описания данных. Многие СУБД используют средства описания данных языков программирования. Для прикладного программиста СУБД должна обеспечить средства передачи команд и интерпретации сообщений, выдаваемых системой. Интерфейс между прикладной программой и СУБД — язык манипулирования данными — встраивается в язык программирования. Запись запрашивается на языке манипулирования данными и считывается в рабочую область прикладной программы; аналогично при включении записи в базу данных прикладная программа помещает ее в рабочую область и выдает команду на языке манипулирования данными. Типичными командами языка манипулирования данными являются: открыть файл или набор записей; закрыть файл или набор записей; определить местонахождение и считать указанный экземпляр записи; передать содержимое указанных элементов данных из определенного экземпляра записи; заменить значение определенных элементов указанного экземпляра записи величинами из рабочей области программы; вставить в набор записей запись из рабочей области; удалить определенный экземпляр записи из последовательности записей; запомнить новый экземпляр записи в базе данных; удалить определенный экземпляр записи из базы данных; переупорядочить записи в группе в убывающей или возрастающей последовательности по указанному ключу.
База данных для библиотеки
... управления БД. Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro. На данный момент файл-серверная технология считается морально устаревшей, поэтому при выборе базы данных для библиотеки ... для их работы требуется отдельный работающий процесс, обычно потребляющий немалый объем памяти. Поэтому для проекта библиотеки этот вариант тоже не подходит. Встраиваемая СУБД - СУБД, которая может ...
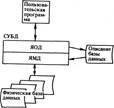
Рис. 2
Системный программист использует язык описания общей логической схемы данных. Этим языком может быть расширение языка программирования, средство СУБД или независимый язык. Для описания размещения данных системный программист использует некоторую форму языка описания физических данных. Этот язык определяет размещение данных на физических устройствах, управление буферизацией, способы адресации и поиска.
При возникновении в системе управления новых задач, связанных с переработкой больших объемов информации, возникает проблема выбора способа организации данных, обеспечивающих ее решение. При этом необходимо рассмотреть возможные способы организации данных и эффективность их применения для решения поставленной задачи: организация данных в виде файлов; использование существующей базы данных (без изменений общей логической схемы данных); разработка новой логической схемы базы данных с использованием универсальной СУБД; разработка базы данных и специальной СУБД.
Любой необходимый для оценки и выбора способа организации базы данных анализ должен начинаться с тщательного изучения потребностей пользователя. На основе изучения пользовательских требований следует составить полный список подлежащих хранению данных с указанием их характеристик и взаимосвязей, список взаимодействующих с базой процессов и пользователей с указанием их приоритетов и заданием параметров доступа к данным, сформулировать требования к времени и стоимости обращения к базе данных. Кроме того, необходимо проанализировать имеющиеся аппаратные средства (размер основной памяти процессора, конфигурацию операционной системы с учетом средств передачи данных, доступных ресурсов и возможностей расширения внешней памяти), а также численность и квалификацию системных и прикладных программистов.
Геномные базы данных как инструмент создания диагностических систем
... картину изученности геномов картир ованных видов, включая информацию о мутантных фенотипах, которая необходима для генетического картирования. Геномные базы данных являются, как правило, частными инициативами и ... работы. Целью курсовой работы является рассмотрение гено мной базы данных в качестве инструмента создания диагностических систем. Исходя из указанной цели, можно выделить частные задачи, ...
Если возникает необходимость организации данных для решения ряда прикладных задач при отсутствии функционирующей базы данных, следует оценить целесообразность использования концепции базы данных для решения поставленных задач. Основой для использования базы данных являются следующие факторы: значительное перекрытие массивов по данным, дублирование накопления и проверки данных, необходимость решения проблемы непротиворечивости элементов; значительное число потребителей информации; значительное число типов запросов; относительное постоянство номенклатуры запросов. Вместе с тем при принятии решения об организации базы данных следует помнить, что ее создание может привести к снижению эффективности отдельных прикладных программ и запросов, так как цель организации БД – повышение эффективности всей системы.
При возникновении новых задач в системе управления с функционирующей базой данных следует оценить возможность использования общей структуры данных для описания предметных областей, т.е. совокупности объектов и процессов новых пользователей на языке подсхем функционирующей базы данных или, если существующая общая логическая схема нуждается в модификации, оценить затраты на внесение необходимых изменений и влияние этих изменений на общие характеристики системы с точки зрения удовлетворения потребностей всех пользователей системы.
В случае принятия решения о разработке новой базы данных возникают задачи выбора универсальной или разработки специализированной СУБД, а также проектирования ее общей логической и физической структуры, причем выбор СУБД, как правило, является основой для проектирования и организации логической и физической структур базы данных.
Существующие СУБД обеспечивают три основных подхода в управлении данными: иерархический, сетевой и реляционный (рис. 3).
Иерархический подход основан на представлении иерархии объектов. Иерархические взаимосвязи непосредственно поддерживаются в физических конструкциях СУБД. Иерархические взаимосвязи являются частным случаем сетевых взаимосвязей. Например, поставщик может поставлять несколько видов товаров, а каждый вид товара может иметь несколько поставщиков. Реляционные системы не вводят различия между объектами и взаимосвязями. Сетевые и иерархические взаимосвязи могут быть представлены в виде двухмерных таблиц, называемых отношениями и обладающих следующими свойствами: каждый элемент таблицы представляет собой один элемент данных (повторяющиеся группы отсутствуют); элементы столбца имеют одинаковую природу, столбцам однозначно присвоены имена; в таблице нет двух одинаковых строк; строки и столбцы могут просматриваться в любом порядке вне зависимости от их информационного содержания. База данных, построенная с помощью отношений, называется реляционной и в идеале обладает следующими преимуществами: возможностью использования неподготовленными пользователями; простотой системы защиты (для каждого отношения задается правомерность доступа); независимостью данных; возможностью построения простого языка манипулирования данными с помощью алгебры отношений.
Хранилища данных
... извлечения и просмотра, в-третьих – средства пополнения хранилищ данных. Типичное хранилище данных как правило отличается от реляционной базы данных: 1) Обычная база данных предназначена для того, чтобы помочь пользователям выполнять повседневную работу, тогда как хранилища данных предназначены ...
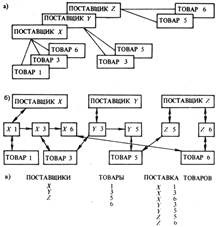
Рис. 3
При выборе универсальной СУБД для реализации конкретной совокупности прикладных программ на основе использования базы данных следует оценить предоставляемый пользователю язык описания данных, язык манипулирования данными и средства поддержания физической базы данных. В качестве характеристик, определяющих язык описания данных, обычно выделяют: наглядность, простоту изучения, степень независимости данных, процедуры защиты от несанкционированного доступа, элементы описания (типы данных, размер и имя и др.), поддерживаемые взаимосвязи (иерархические, сетевые, реляционные).
Среди характеристик языков манипулирования данными следует выделить: представляемые средства доступа (в физической последовательности, по значению элемента данных, по ключу), совместимость с базовыми (высокоуровневыми) языками программирования, простоту изучения и использования, независимость данных, возможности и средства одновременного использования базы несколькими прикладными программами.
3. Выбор СУБД
Он осуществляется с учетом потребностей пользователя одним из следующих методов: анализа возможностей, экспериментальной проверки, имитации и моделирования.
Метод анализа возможностей основан на балльной оценке приведенных выше характеристик СУБД с точки зрения требований пользователя. Каждая характеристика изучается с двух позиций — присутствует ли она в предлагаемой СУБД и каково ее качество. Качество ранжируется по стандартной шкале. Коэффициент ранжирования умножается на выделенный для данной составляющей вес, и взвешенные по каждой составляющей баллы суммируются.
Метод экспериментальной проверки состоит в создании определенной прикладной среды и получении с ее помощью эксплуатационных характеристик заданной программно-аппаратной системы. Для экспериментальной проверки необходимо спроектировать и загрузить типовую базу данных; затем с использованием языка манипулирования данными СУБД промоделировать требования по обработке существующих и ожидаемых прикладных программ и выполнить экспериментальную проверку рассматриваемых СУБД.
В методе имитации и моделирования работы СУБД применяют математические выражения, определяющие зависимость одного из параметров от других. Например, время обращения можно представить в виде функции от числа обращений к диску, количества передаваемой информации и процессорного времени формирования отклика на запрос. Так как перечисленные параметры зависят от способа хранения данных и способа доступа к ним, для различных СУБД требуются разные модели. Если эти модели разработаны, их можно использовать для оценки времени и стоимости обработки при использовании различных СУБД, задавая разнообразные условия (изменяя размеры базы данных, методы доступа, коэффициенты блокирования и т.п.).
Неквалифицированный проектировщик может наложить ограничения конкретной СУБД уже на ранней стадии проектирования базы данных. При этом пользовательские требования искусственно задаются иерархическими и сетевыми структурами определенной СУБД без рассмотрения других возможных проектных решений. Такой подход может привести к уменьшению эффективности системы.
БАЗЫ ДАННЫХ И ИХ ЗАЩИТА
... Временные или временные базы данных - это базы данных, в которых хранятся связанные со временем данные и есть средства управления этой информацией. Главное отличие темпоральных систем управления базами данных (СУБД) от обычных реляционных СУБД заключается в том, что ...
Ниже приведены краткие характеристики некоторых универсальных СУБД.
СУБД ИНЭС ориентирована на решение информационно-поисковых задач главным образом с использованием диалога. В ней обеспечиваются возможности быстрого обращения к базе для получения данных справочного характера и эффективного просмотра больших объемов данных при составлении сводок и при формировании исходных массивов для решения экономических задач.
В системе допускается обращение к данным из прикладных программ пользователя, написанных на языке АССЕМБЛЕР, ПЛ/1, КОБОЛ, АЛГОЛ-60, ФОРТРАН-4.
Используются специальные входные языки (язык ввода экономических показателей, язык ввода документов) и язык запросов, которые удовлетворяют основным требованиям, предъявляемым к языкам описания данных и языкам манипулирования данными.
Для работы с данными, имеющими иерархическую структуру, служит специальный метод доступа. СУБД ИНЭС имеет систему формирования выходных сообщений и систему визуализации сообщений, которые позволяют пользователю задавать структуру документа и его реквизиты, осуществлять поиск, изменение и корректировку данных и вывод их на дисплей.
СУБД КВАНТ-М представляет собой систему реального времени, предназначенную для работы на мини-ЭВМ и используемую для решения задач в информационно-поисковых и справочных системах (фактографических, библиографических, резервирования заказов и т.п.).
Пользовательские программы могут быть написаны на языках КОБОЛ, ФОРТРАН, БЕЙСИК-2 и обращаются к базе данных с помощью САМ-интерфейса.
СУБД КВАНТ-М поддерживает базу данных, состоящую из набора массивов (файлов).
Записи массива имеют одинаковую структуру и уникальный последовательный номер (ISN).
Записи состоят из полей, которые являются минимальной единицей данных в базе. Поле может быть объявлено ключом. Для описания данных в файлах создается схема, содержащая имена полей записей, их тип и признак, указывающий, является ли поле ключом. Для пользователей создается одна или несколько подсхем, к которым они имеют доступ.
Физическая структура данных использует инвертированные списки значений ключей и обеспечивает независимость адресации от физического расположения данных. Система обеспечивает следующие типы доступа: последовательный по ISN; в логической последовательности; по запросу.
Языком манипулирования данными является язык КВАНТ СКРИПТ-М. Это англоподобный диалоговый язык, предназначенный для эффективного поиска и выделения записей в базе данных и вывода их на дисплей.
В последнее время организован выпуск быстродействующих персональных ЭВМ с большой оперативной и внешней памятью, с возможностью их объединения в локальную вычислительную сеть. Для этих ЭВМ появились и продолжают появляться универсальные СУБД, предоставляющие пользователю средства и удобства иногда более богатые, чем у мини-ЭВМ и больших ЭВМ. Этот процесс еще не установился, в связи с чем не имеет смысла приводить в учебнике характеристики этих СУБД.
4. Специализированные базы данных
Процесс проектирования специализированной базы данных включает: логическое проектирование, физическое проектирование, разработку специализированной СУБД.
Логическое проектирование предусматривает анализ. требований, моделирование данных прикладных программ и их интеграцию, разработку логической схемы. Анализ требований пользователей проводится с применением стандартных методов системного анализа: документирования, обследования, имитированных отчетов. В результате анализа требований получают систематизированные наборы данных и спецификации обработки с использованием стандартных определений данных, минимизирующих противоречия в разработанных спецификациях.
Архитектура базы данных
... организации описание структур хранимых данных, а СУБД, посредством которой эта ИС будет создаваться и поддерживаться, обязана иметь для этого определенные возможности. Трехуровневая архитектура базы данных Как ... состоять из набора экземпляров записей, содержащих информацию об отдельных, плюс набор экземпляров, содержащих информацию о деталях и т.д. Концептуальная запись вовсе не обязательно должна ...
Модель данных предназначена для отображения пользовательской среды. Так как база данных создается для многих пользователей, этап интеграции призван разрешить противоречия между требованиями пользователей в процессе моделирования.
На этапе создания схемы модели пользователей необходимо объединить в одну, из которой можно выделять все альтернативные представления. Задача синтеза оптимальной логической структуры базы данных состоит в определении оптимальной в смысле принятого критерия логической структуры, обеспечивающей реализацию совокупности запросов всех пользователей системы. Среди используемых критериев синтеза логической структуры базы данных можно выделить минимум стоимости хранения, обновления и передачи информации за определенный период, минимум суммарных информационных потоков, минимальный объем хранимой информации, минимум стоимости обновления информации, максимум быстродействия, максимум надежности. Если спецификации требований и модели данных не зависят от СУБД, то схема базы данных представляет собой ее описание на языке описания данных. В дополнение к схеме разрабатываются описания подмножеств базы данных (подсхемы) пользователей. Проектирование физической базы данных включает физическое представление данных, выбор и документирование методов доступа, размещение данных.
Основываясь на логической схеме, проектировщик физической организации должен определить представление каждого элемента данных, записей и массивов. Для каждого физического массива необходимо установить его размер. При определении физического представления данных необходимо учитывать следующие факторы: экономию памяти, минимизацию избыточности (использование ссылок или указателей), способ обработки (последовательная, произвольная) и адресации, коэффициент активности массива и записей (определяет выбор устройств с прямым или последовательным доступом), независимость данных, время отклика на запрос (определяет организацию данных и тип запоминающего устройства).
Специфика задач, решаемых на основе разрабатываемой базы данных, требования пользователя и логическая схема базы данных являются основой для выбора способа адресации и организации поиска данных. Среди способов адресации различают: последовательное сканирование, блочный поиск, двоичный поиск, индексно-последовательный способ, прямую адресацию, перемешивание и различные их комбинации.
Последовательное сканирование связано с проверкой ключа каждой записи. Способ может быть эффективен только при пакетной обработке последовательных массивов на магнитной ленте.
Блочный поиск используется в случаях упорядоченных по ключу последовательных массивов. Записи группируются в блоки и каждой блок проверяется, пока не будет найден нужный блок, записи которого считываются.
При двоичном поиске поисковая область каждый раз делится пополам, и ключ полученной записи сравнивается с поисковым ключом. Двоичный поиск обычно не пригоден для устройств с прямым доступом и применяется при поиске индексов массивов.
Проблемы проектирования баз данных
... базу данных как набор записей с информацией об отделах плюс набор записей с информацией о служащих и ничего не знать о записях с информацией ... базы данных 1.2 Структура системы баз данных Структурой системы ... базы данных, в котором каждый сотрудник представлен записью на языке COBOL, содержащей, опять же, два поля (в данном случае опущен размер оклада). Тип записи определен с помощью обычного описания ...
Индексно-последовательный способ адресации использует индексы. Индекс верхнего уровня указывает местоположение индекса нижнего уровня, который указывает место расположения блока записей. Блок записей либо сканируется, либо в нем проводится двоичный или блочный поиск. Метод предусматривает упорядоченность записей по ключу. В случае произвольного массива применяется индексно-произвольный способ. Однако при этом требуется значительно больший по размерам индекс, так как он должен содержать по одному элементу для каждой записи массива, а не для блока записей.
Прямая адресация предусматривает некоторое преобразование ключа в адрес. Существует много методов преобразования ключа в адрес в массиве. Наиболее простой способ состоит в указании во входном сообщении относительного мониторного адреса записи. В некоторых приложениях адрес вычисляется на основе идентификаторов объектов.
Способ перемешивания состоит в том, что ключ элемента данных преобразуется в квазислучайное число, которое используется для определения места расположения записи.
При проектировании физической структуры базы данных необходимо определить и документировать способ доступа к каждому типу записей, определить записи, доступ к которым проводится непосредственно по ключам, и записи, доступ к которым осуществляется с помощью указателей из других записей или индексов. Каждому массиву в зависимости от метода доступа необходимо выделить место на физических устройствах (магнитных дисках, лентах).
При этом данные размещаются таким образом, чтобы обеспечить приоритет часто используемым данным или максимизировать степень близости хранимых данных.
Наиболее широко используемым является индексно-последовательный способ адресации. При этом можно использовать два метода доступа – ISAM и VSAM. В методе доступа ISAM записи группируются так, чтобы они могли располагаться на отдельных дорожках цилиндров модуля дисков, а одна дорожка на каждом цилиндре отводится для индексов, указывающих на записи, расположенные на данном цилиндре. При необходимости внесения новых данных они помещаются в область переполнения (в дорожку индексов включаются также указатели на области переполнения).
Метод доступа VSAM аналогичен методу ISAM, однако метод VSAM не зависит от типа оборудования и не оперирует такими категориями, как дорожки и цилиндры. Вместо цилиндров, разделенных на дорожки, используются управляемые области, в свою очередь подразделяемые на управляемые интервалы. В методе VSAM для одной управляемой области имеется один набор указателей (индекс).
Проектирование специализированной СУБД предусматривает разработку языка описания данных, языка манипулирования данными и средства поддержания физической базы данных. Основные требования, которым должны удовлетворять языки описания данных и манипулирования данными, были определены при рассмотрении вопроса выбора универсальной СУБД. Наиболее распространенным языком описания данных программиста (подсхем) является раздел данных КОБОЛа, для описания схем и физической структуры базы данных в современных СУБД, как правило, разрабатываются свои собственные языки описания данных. Ассоциацией по языкам систем обработки данных (CODASYL) предложен язык описания данных, который используется как для логического описания данных, так и для описания их физической организации.
Иерархические модели данных
... иерархической модели данных. Методы исследования. При написании курсовой работы был произведен комплексный анализ. Основными методами в работе явились методы анализа: метод описания ... с информацией о служащих, содержит в себе описание структуры данных (ОСД), хранящихся в этом файле. Когда структура данных ... элементом данных". 1.2 Базы данных В самом общем смысле база данных - это набор записей и ...
5. Распределенные базы данных
В связи с созданием и развитием в настоящее время ряда АСУ на базе сетей ЭВМ актуальным является проектирование распределенных баз данных (РБД).
Распределенная база данных представляет собой систему информационно-взаимосвязанных и определенным образом взаимодействующих локальных баз данных (ЛБД), имеющих свое информационное содержание и структуру. По существу РБД представляет собой рассредоточенную систему памяти, хранящей все данные, необходимые соответствующей АСУ. Особенность ее в том, что фрагменты сформированной логической структуры размещаются в территориально удаленных базах данных. Физическая реализация связанности РБД осуществляется организацией информационных потоков внутри ЛБД и между ними по каналам связи.
Основной проблемой при создании РБД является размещение данных; это определяет такие характеристики РБД, как объемы хранимых и обновляемых данных, интенсивность потоков информации и надежность систем.
Проектирование РБД может проходить в условиях:
- а) создание АСУ только начинается и стоит задача выбора оптимальной структуры РБД и размещения отдельных ЛБД;
- б) существует определенное количество ЛБД и ВЦ и стоит задача размещения дополнительного числа ЛБД и оптимального изменения структуры связей в системе;
- в) формирование географии и структуры системы закончено и стоит задача оптимального переразмещения массивов и изменения топологии связей.
Наиболее характерными задачами при проектировании РБД являются определение структуры РБД, определение топологии связей, выбор стратегии поиска и обновления информации, выбор системы управления РБД.
Различают централизованные, децентрализованные и комбинированные структуры РБД. Наиболее широкое распространение получили комбинированные РБД, для которых характерно наличие центральной базы данных, хранящей общесистемную информацию о размещении массивов в РБД. Число ЛБД на каждом уровне иерархии определяется ограничениями на объемы хранимой информации и ограничениями на стоимость создания ЛБД. Размещение ЛБД зависит от размещения потребителей и источников информации.
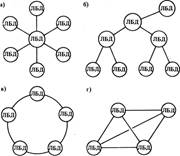
Рис. 4
Выбор топологии сети ЛБД определяется характером их информационных взаимосвязей, направлением и интенсивностью информационных потоков, необходимой надежностью и достоверностью передачи информации. Обычно пользователи прикрепляются к одной ЛБД и через эту ЛБД связываются с остальными базами данных в РБД. Различают следующие типы структур связей ЛБД в РБД: радиальную, радиально-узловую, кольцевую, каждый с каждым, комбинированную (рис. 4, а — г).
Наиболее надежной, с быстрым поиском информации является система со структурой «каждый с каждым». Информационные связи такого типа характерны для объектов, подчиненных друг другу только функционально.
Стратегия поиска влияет на количество и размещение структурной и потоки запросной информации. При отсутствии информации, затребованной пользователем в ближайшей ЛБД, могут быть предложены следующие стратегии поиска:
1) по структурной информации о размещении данных в РБД происходит поиск необходимой ЛБД и обращение к этой ЛБД;
2) осуществляется поиск в ЛБД более высокого ранга; если необходимая информация отсутствует, анализируется структурная информация о содержании всех подчиненных ЛБД; если необходимая информация отсутствует, переходят к ЛБД более высокого уровня иерархии;
3) осуществляется обращение в управляющую ЛБД, где хранится структурная информация о всех ЛБД;
4) осуществляется опрос всех ЛБД либо параллельно, либо последовательно.
Стратегия 1 обеспечивает минимальные объемы запросной информации, но в каждой ЛБД необходимо хранить структурную информацию о размещении массивов в РБД.
Стратегия 2 характерна для иерархических систем, в которых преобладают информационные потоки сверху вниз.
Стратегия 3 минимизирует структурную информацию.
Стратегия 4 отличается большими потоками запросной информации.
Функционирование РБД предполагает наличие в ней потоков обновления информации. Среди стратегий обновления можно выделить следующие: обновление всех дублируемых массивов по всем ЛБД выполняет источник информации; источник обновляет информацию только в ближайшей ЛБД, все остальные дублируемые массивы обновляются по инициативе этой ЛБД; обновление дублируемых массивов проводится по алгоритму (например, минимизирующему суммарные потоки обновления).
Стратегия обновления должна обеспечивать заданную надежность, достоверность и быстродействие РБД. Разработка и внедрение эффективных систем управления РБД находятся в настоящее время на начальном этапе. Основной критерий при разработке системы управления РБД – минимальная трудоемкость создания и внедрения ее математического обеспечения. Задача может решаться доработкой и подстройкой существующих СУБД или созданием эффективных специальных систем управления РБД.