
Данная работа не является научным трудом, не является выпускной квалификационной работой и представляет собой результат обработки, структурирования и форматирования собранной информации, предназначенной для использования в качестве источника материала при самостоятельной подготовки учебных работ.
Министерство образования РФ.
Новгородский государственный университет имени Ярослава Мудрого.
Кафедра математики и информатики.
Лабораторная работа №6
по дисциплине «Информатика»
«Архивация данных»
ОТЧЕТ.
Преподаватель
Винник Людмила Ивановна
_____________
студент
*****************
Гр. 3311.
_____________
Великий Новгород
2004.
1. ЦЕЛЬ РАБОТЫ
Целью работы является изучение основных видов программ-архиваторов, алгоритмов архивации данных, приобретение практических навыков их использования.
2. ОСНОВНЫЕ ТЕОРЕТИЧЕСКИЕ ПОЛОЖЕНИЯ
2.1 Применение архиваторов
Раньше в вычислительных машинах для хранения больших объемов информации в течение длительного времени использовались накопители на магнитных лентах, которые обладали колоссальной емкостью, а сжатие информации на диске было нерациональным решением, так как работа с ней в таком виде отнимала драгоценное машинное время. Необходимость в архиваторах возникла, когда появились персональные компьютеры, и для хранения в них информации использовались дискеты и жесткие диски первоначально небольшой емкости. Повышение скорости работы процессоров персональных компьютеров в середине 80-х годов позволило создать утилиты, сжимающие информацию в два раза.
С развитием компьютера стали увеличиваться и объемы информации хранимой в нем, что в свою очередь привело к развитию технологий по хранению этой информации в сжатом виде, то есть в архивах. Для этого было придумано множество программ осуществляющих архивацию информации.
Архиваторы в основном использовались для резервного копирования и переноса информации. При хранении копий файлов в сжатом виде они занимают меньше места, к тому же удобнее оперировать с одним или несколькими файлами, чем с большим количеством файлов и директорий. Не потеряли архиваторы актуальности и теперь, однако требования, предъявляемые пользователям к этой категории программных продуктов, существенно изменились. Если раньше едва ли не самым важным было требование по максимальному сжатию информации, хотя бы в силу дороговизны на тот момент носителей информации — в первую очередь распространялись архиваторы, удовлетворяющие именно этому требованию, то теперь ситуация значительно изменилась и на первое место встают простота и удобство в использовании.
Какой вид связи используется в словосочетании подчинение или
... сочинения — подчинения. Средства выражения подчинения в простом и сложном предложениях различны. В простом предложении в выражении подчинения принимают участие разные морфологические словоизменительные формы (см. Лексема и форма слова). Подчинительная связь в ... может выражать значение сочинительной связи «в чистом виде»: Он сказал, что кот ... союз но — противительные, союз или — разделительные и т. д. ...
Еще одним немаловажным требованием, предъявляемым к архиваторам при переносе информации, была его распространенность, т. е. чтобы при передаче информации не приходилось в придачу передавать и сам архиватор
2.2 Понятие процесса архивации файлов
Одним из наиболее широко распространенных видов сервисных программ являются программы, предназначенные для архивации, упаковки файлов путем сжатия хранимой в них информации.
Сжатие информации — это процесс преобразования информации, хранящейся в файле, к виду, при котором уменьшается избыточность в ее представлении и соответственно требуется меньший объем памяти для хранения.
Сжатие информации в файлах производится за счет устранения избыточности различными способами, например за счет упрощения кодов, исключения из них постоянных битов или представления повторяющихся символов или повторяющейся последовательности символов в виде коэффициента повторения и соответствующих символов. Применяются различные алгоритмы подобного сжатия информации.
Сжиматься могут как один, так и несколько файлов, которые в сжатом виде помещаются в так называемый архивный файл или архив.
файлов, дате и времени их создания или модификации, размерах и т.п.
Целью упаковки файлов обычно являются обеспечение более компактного размещения информации на диске, сокращение времени и соответственно стоимости передачи информации по каналам связи в компьютерных сетях. Кроме того, упаковка в один архивный файл группы файлов существенно упрощает их перенос с одного компьютера на другой, сокращает время копирования файлов на диски, позволяет защитить информацию от несанкционированного доступа, способствует защите от заражения компьютерными вирусами.
Степень сжатия зависит от используемой программы, метода сжатия и типа исходного файла. Наиболее хорошо сжимаются файлы графических образов, текстовые файлы и файлы данных, для которых степень сжатия может достигать 5 — 40%, меньше сжимаются файлы исполняемых программ и загрузочных модулей — 60 — 90%. Почти не сжимаются архивные файлы. Программы для архивации отличаются используемыми методами сжатия, что соответственно влияет на степень сжатия.
Архивация (упаковка) — помещение (загрузка) исходных файлов в архивный файл в сжатом или несжатом виде. Разархивация (распаковка) — процесс восстановления файлов из архива точно в таком виде, какой они имели до загрузки в архив. При распаковке файлы извлекаются из архива и помещаются на диск или в оперативную память;
— Архиваторы — это программы, позволяющие создавать и обрабатывать архивные копии файлов. При этом архивные копии имеют меньший размер, чем оригиналы. С помощью специальных алгоритмов сжатия из файлов удаляется вся избыточная информация, а при применении обратных алгоритмов распаковки архивная копия восстанавливается в первоначальном виде.
Программы-архиваторы позволяют создавать и такие архивы, для извлечения из которых содержащихся в них файлов не требуются какие-либо программы, так как сами архивные файлы могут содержать программу распаковки. Такие архивные файлы называются самораспаковывающимися.
Информационный процесс. Обработка информации
... процесс классификации. Формализованная модель обработки информации Обратимся теперь к вопросу о том, в чем сходство и различие процессов обработки информации, связанных с различными составляющими информационного процесса, ... слово. 1. Что такое информация, информационный процесс. В обыденной жизни информацию отождествляют с понятиями "сообщение", "сведения", "данные", "знания". Такое соотношение ...
Самораспаковывающийся архивный файл — это загрузочный, исполняемый модуль, который способен к самостоятельной разархивации находящихся в нем файлов без использования программы-архиватора.
Самораспаковывающийся архив получил название SFX-архив (SelF-eXtracting).
Архивы такого типа в MS DOS обычно создаются в форме .ЕХЕ-файла.
многотомными.
Сжатие информации — проблема, имеющая достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая (история) обычно шла параллельно с историей развития проблемы кодирования и шифровки информации.
Все алгоритмы сжатия оперируют входным потоком информации, минимальной единицей которой является бит, а максимальной — несколько бит, байт или несколько байт.
Целью процесса сжатия, как правило, есть получение более компактного выходного потока информационных единиц из некоторого изначально некомпактного входного потока при помощи некоторого их преобразования.
Основными техническими характеристиками процессов сжатия и результатов их работы являются:
- степень сжатия (compress rating) или отношение (ratio) объемов исходного и результирующего потоков;
- скорость сжатия — время, затрачиваемое на сжатие некоторого объема информации входного потока, до получения из него эквивалентного выходного потока;
- качество сжатия — величина, показывающая на сколько сильно упакован выходной поток, при помощи применения к нему повторного сжатия по этому же или иному алгоритму.
2.3.
Алгоритмы архивации данных
Все способы сжатия можно разделить на две категории: обратимое (сжатие без потерь) и необратимое сжатие.
Под необратимым сжатием подразумевают такое преобразование входного потока данных, при котором выходной поток, основанный на определенном формате информации, представляет, с некоторой точки зрения, достаточно похожий по внешним характеристикам, на входной поток объект, однако отличается от него объемом.
Такие подходы и алгоритмы используются для сжатия, например данных растровых графических файлов с низкой степенью повторяемости байтов в потоке. При таком подходе используется свойство структуры формата графического файла и возможность представить графическую картинку приблизительно схожую по качеству отображения (для восприятия человеческим глазом) несколькими (а точнее n) способами. Поэтому, кроме степени или величины сжатия, в таких алгоритмах возникает понятие качества, т.к. исходное изображение в процессе сжатия изменяется, то под качеством можно понимать степень соответствия исходного и результирующего изображения, оцениваемая субъективно, исходя из формата информации. Для графических файлов такое соответствие определяется визуально, хотя имеются и соответствующие интеллектуальные алгоритмы и программы. Необратимое сжатие невозможно применять в областях, в которых необходимо иметь точное соответствие информационной структуры входного и выходного потоков. Данный подход реализован в популярных форматах представления видео и фото информации, известных как JPEG и JFIF алгоритмы и JPG и JIF форматы файлов.
Сжатие информации в ПК
... Хаффмановского и арифметического методов в которой сжатие основано на свойстве "потока символов" иметь повторяющиеся участки. Поток символов - это исходные данные для сжатия (например текстовый файл, массив). Основная ... в тех случаях, когда степень сжатия важнее, чем временные затраты на сжатие информации. При словарном способе группы последовательных символов или "фраз" заменяются кодом. Замененная ...
Обратимое сжатие всегда приводит к снижению объема выходного потока информации без изменения его информативности, т.е. — без потери информационной структуры.
Более того, из выходного потока, при помощи восстанавливающего или декомпрессирующего алгоритма, можно получить входной, а процесс восстановления называется декомпрессией или распаковкой и только после процесса распаковки данные пригодны для обработки в соответствии с их внутренним форматом.
Перейдем теперь непосредственно к алгоритмическим особенностям обратимых алгоритмов и рассмотрим важнейшие теоретические подходы к сжатию данных, связанные с реализацией кодирующих систем и способы сжатия информации.
2.3. 1 Алгоритмы сжатия без потерь
2.3.1.1. Сжатие способом кодирования серий (RLE)
Наиболее известный простой подход и алгоритм сжатия информации обратимым путем — это кодирование серий последовательностей (Run Length Encoding — RLE).
Суть методов данного подхода состоит в замене цепочек или серий повторяющихся байтов или их последовательностей на один кодирующий байт и счетчик числа их повторений.
Например:
44 44 44 11 11 11 11 11 01 33 FF 22 22 — исходная последовательность
03 44 05 11 01 01 01 33 01 FF 02 22 — сжатая последовательность
Первый байт указывает сколько раз нужно повторить следующий байт
Если первый байт равен 00, то затем идет счетчик, показывающий сколько за ним следует неповторяющихся данных.
Данные методы, как правило, достаточно эффективны для сжатия растровых графических изображений (BMP, PCX, TIF, GIF), т.к. последние содержат достаточно много длинных серий повторяющихся последовательностей байтов.
Недостатком метода RLE является достаточно низкая степень сжатия.
2.3.1.2 Алгоритм Хаффмана
Сжимая файл по алгоритму Хаффмана первое что мы должны сделать — это необходимо прочитать файл полностью и подсчитать сколько раз встречается каждый символ из расширенного набора ASCII.
Если мы будем учитывать все 256 символов, то для нас не будет разницы в сжатии текстового и EXE файла.
После подсчета частоты вхождения каждого символа, необходимо просмотреть таблицу кодов ASCII и сформировать бинарное дерево.
Пример:
Мы имеем файл длинной в 100 байт и имеющий 6 различных символов в себе . Мы подсчитали вхождение каждого из символов в файл и получили следующее :
![]()
Теперь мы берем эти числа и будем называть их частотой вхождения для каждого символа.
![]()
Мы возьмем из последней таблицы 2 символа с наименьшей частотой. В нашем случае это D (5) и какой либо символ из F или A (10), можно взять любой из них например A.
Сформируем из «узлов» D и A новый «узел», частота вхождения для которого будет равна сумме частот D и A :

Номер в рамке — сумма частот символов D и A. Теперь мы снова ищем два символа с самыми низкими частотами вхождения. Исключая из просмотра D и A и рассматривая вместо них новый «узел» с суммарной частотой вхождения. Самая низкая частота теперь у F и нового «узла». Снова сделаем операцию слияния узлов :
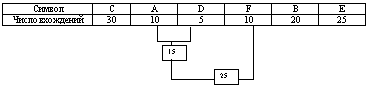
Рассматриваем таблицу снова для следующих двух символов ( B и E ).
Мы продолжаем в этот режим пока все «дерево» не сформировано, т.е. пока все не сведется к одному узлу.
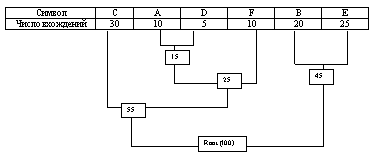
Теперь когда наше дерево создано, мы можем кодировать файл . Мы должны всегда начинать из корня ( Root ).
Кодируя первый символ (лист дерева С) Мы прослеживаем вверх по дереву все повороты ветвей и если мы делаем левый поворот, то запоминаем 0-й бит, и аналогично 1-й бит для правого поворота. Так для C, мы будем идти влево к 55 ( и запомним 0 ), затем снова влево (0) к самому символу . Код Хаффмана для нашего символа C — 00. Для следующего символа ( А ) у нас получается — лево,право,лево,лево , что выливается в последовательность 0100. Выполнив выше сказанное для всех символов получим
C = 00 ( 2 бита )
A = 0100 ( 4 бита )
D = 0101 ( 4 бита )
F = 011 ( 3 бита )
B = 10 ( 2 бита )
E = 11 ( 2 бита )
При кодировании заменяем символы на данные последовательности.
2.3.1.3 Арифметическое кодирование
Совершенно иное решение предлагает т.н. арифметическое кодирование. Арифметическое кодирование является методом, позволяющим упаковывать символы входного алфавита без потерь при условии, что известно распределение частот этих символов и является наиболее оптимальным, т.к. достигается теоретическая граница степени сжатия.
Предполагаемая требуемая последовательность символов, при сжатии методом арифметического кодирования рассматривается как некоторая двоичная дробь из интервала [0, 1).
Результат сжатия представляется как последовательность двоичных цифр из записи этой дроби.
Идея метода состоит в следующем: исходный текст рассматривается как запись этой дроби, где каждый входной символ является «цифрой» с весом, пропорциональным вероятности его появления. Этим объясняется интервал, соответствующий минимальной и максимальной вероятностям появления символа в потоке.
Пример.
Пусть алфавит состоит из двух символов: a и b с вероятностями соответственно 0,75 и 0,25.
Рассмотрим наш интервал вероятностей [0, 1).
Разобьем его на части, длина которых пропорциональна вероятностям символов. В нашем случае это [0; 0,75) и [0,75; 1).
Суть алгоритма в следующем: каждому слову во входном алфавите соответствует некоторый подинтервал из интервала [0, 1) а пустому слову соответствует весь интервал [0, 1).
После получения каждого следующего символа интервал уменьшается с выбором той его части, которая соответствует новому символу. Кодом цепочки является интервал, выделенный после обработки всех ее символов, точнее, двоичная запись любой точки из этого интервала, а длина полученного интервала пропорциональна вероятности появления кодируемой цепочки.
Применим данный алгоритм для цепочки «aaba»:
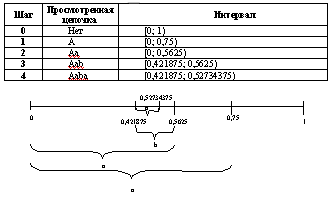
Границы интервала вычисляются так берется расстояние внутри интервала (0,5625-0,421875=0,140625), делится на частоты [0; 0,10546875) и [0,10546875; 1) и находятся новые границы [0,421875; 0,52734375) и [0,52734375; 0,5625).
В качестве кода можно взять любое число из интервала, полученного на шаге 4, например, 0,43.
Алгоритм декодирования работает аналогично кодирующему. На входе 0,43 и идет разбиение интервала.
Продолжая этот процесс, мы однозначно декодируем все четыре символа. Для того, чтобы декодирующий алгоритм мог определить конец цепочки, мы можем либо передавать ее длину отдельно, либо добавить к алфавиту дополнительный уникальный символ — «конец цепочки».
2.3.1.4 Алгоритм Лемпеля – Зива — Велча (Lempel-Ziv-Welch — LZW)
Данный алгоритм отличают высокая скорость работы как при упаковке, так и при распаковке, достаточно скромные требования к памяти и простая аппаратная реализация.
Недостаток — низкая степень сжатия по сравнению со схемой двухступенчатого кодирования.
Предположим, что у нас имеется словарь, хранящий строки текста и содержащий порядка от 2-х до 8-ми тысяч пронумерованных гнезд. Запишем в первые 256 гнезд строки, состоящие из одного символа, номер которого равен номеру гнезда.
Алгоритм просматривает входной поток, разбивая его на подстроки и добавляя новые гнезда в конец словаря. Прочитаем несколько символов в строку s и найдем в словаре строку t — самый длинный префикс s.
Пусть он найден в гнезде с номером n. Выведем число n в выходной поток, переместим указатель входного потока на length(t) символов вперед и добавим в словарь новое гнездо, содержащее строку t+c, где с — очередной символ на входе (сразу после t).
Алгоритм преобразует поток символов на входе в поток индексов ячеек словаря на выходе.
При практической реализации этого алгоритма следует учесть, что любое гнездо словаря, кроме самых первых, содержащих одно-символьные цепочки, хранит копию некоторого другого гнезда, к которой в конец приписан один символ. Вследствие этого можно обойтись простой списочной структурой с одной связью.
Пример: ABCABCABCABCABCABC — 1 2 3 4 6 5 7 7 7
|
1 |
A |
|
2 |
B |
|
3 |
C |
|
4 |
AB |
|
5 |
BC |
|
6 |
CA |
|
7 |
ABC |
|
8 |
CAB |
|
9 |
BCA |
2.3.1.5 Двухступенчатое кодирование. Алгоритм Лемпеля-Зива
Гораздо большей степени сжатия можно добиться при выделении из входного потока повторяющихся цепочек — блоков, и кодирования ссылок на эти цепочки с построением хеш таблиц от первого до n-го уровня.
Метод, о котором и пойдет речь, принадлежит Лемпелю и Зиву и обычно называется LZ-compression.
Суть его состоит в следующем: упаковщик постоянно хранит некоторое количество последних обработанных символов в буфере. По мере обработки входного потока вновь поступившие символы попадают в конец буфера, сдвигая предшествующие символы и вытесняя самые старые.
Размеры этого буфера, называемого также скользящим словарем (sliding dictionary), варьируются в разных реализациях кодирующих систем.
Экспериментальным путем установлено, что программа LHarc использует 4-килобайтный буфер, LHA и PKZIP — 8-ми, а ARJ — 16-килобайтный.
Затем, после построения хеш таблиц алгоритм выделяет (путем поиска в словаре) самую длинную начальную подстроку входного потока, совпадающую с одной из подстрок в словаре, и выдает на выход пару (length, distance), где length — длина найденной в словаре подстроки, а distance — расстояние от нее до входной подстроки (то есть фактически индекс подстроки в буфере, вычтенный из его размера).
В случае, если такая подстрока не найдена, в выходной поток просто копируется очередной символ входного потока.
В первоначальной версии алгоритма предлагалось использовать простейший поиск по всему словарю. Однако, в дальнейшем, было предложено использовать двоичное дерево и хеширование для быстрого поиска в словаре, что позволило на порядок поднять скорость работы алгоритма.
Таким образом, алгоритм Лемпеля-Зива преобразует один поток исходных символов в два параллельных потока длин и индексов в таблице (length + distance).
Очевидно, что эти потоки являются потоками символов с двумя новыми алфавитами, и к ним можно применить один из упоминавшихся выше методов (RLE, кодирование Хаффмана или арифметическое кодирование).
Так мы приходим к схеме двухступенчатого кодирования — наиболее эффективной из практически используемых в настоящее время. При реализации этого метода необходимо добиться согласованного вывода обоих потоков в один файл. Эта проблема обычно решается путем поочередной записи кодов символов из обоих потоков.
Пример:
Первая ступень
abcabcabcabcabc — 1 а 1 b 1 c 3 3 6 3 9 3 12 3
Вторая ступень — исключение большой группы повторяющихся последовательностей
1 а 1 b 1 c 12 3
и сжатие RLE, кодирование Хаффмана , арифметическое кодирование
Перечень программ сжатия с кратким указанием алгоритмов их работы.
PKPAK 3.61:
Метод Packed — алгоритм RLE.
Метод Crunched — алгоритм LZW.
Метод Squashed — двухпроходное статическое кодирование Хаффмана.
PKZIP 1.10:
Метод Shrinked — модифицированный алгоритм LZW с частичной очисткой словаря и переменной длиной кода.
Метод Imploded — модифицированный алгоритм Лемпеля-Зива и
статическое кодирование Хаффмана.
LHArc:
Алгоритм Лемпеля-Зива и динамическое кодирование Хаффмана.
LHA:
Алгоритм Лемпеля-Зива и статическое кодирование Хаффмана.
ARJ:
Алгоритм Лемпеля-Зива и оригинальный метод кодирования
2.3.2 Алгоритмы сжатия с потерями
2.3.2.1 Особенности сжатия графики
Напомним, что растровые изображения представляют собой двумерный массив чисел — пикселей, а изображения можно подразделить на две группы: с палитрой и без нее. У первых в пикселе хранится число — индекс в некотором одномерном векторе цветов, называемом палитрой (из 16 и 256 цветов).
Изображения без палитры бывают в какой-либо системе цветопредставления и в градациях серого. При использовании некой системы цветопредставления каждый пиксель является структурой, полями которой являются компоненты цвета (например, RGB и CMYK).
На заре компьютерной эры для сжатия графики применялись традиционные алгоритмы, рассмотренные выше. С появлением новых типов изображений эти алгоритмы утратили эффективность. Многие изображения практически не сжимались, хотя обладали явной избыточностью. Тогда и появились алгоритмы с потерей информации. Как правило, в них можно задавать коэффициент сжатия (т. е. степень потерь качества).
Алгоритмы сжатия с потерями не рекомендуется использовать при сжатии изображений, которые затем будут предназначены для печати с высоким качеством или для обработки с помощью ПО распознавания образов.
2.3.2.2 Фрактальное сжатие
Так называемые фрактальные алгоритмы обеспечивают степень сжатия изображения до 1:2000 (формат FIF).
Кроме того, при разархивации изображение можно масштабировать. Уникальность этих алгоритмов в том, что изображение не дробится на квадраты и учитывается не близость цветов в локальной области, а подобие разных по размеру областей изображения.
Фрактальные алгоритмы ориентированы на полноцветные изображения и изображения в градациях серого. Они требуют огромных вычислительных мощностей при архивации, зато распаковка менее ресурсоемка, чем JPEG.
За годы с момента возникновения первой программы данного типа написаны сотни различных архиваторов, поддерживающих различные форматы архивов. На момент становления и развития архиваторов самым распространенным форматом был ARJ, на втором месте почти сразу за ним ZIP, с некоторым отрывом следовали такие архиваторы, как ARC, ACE, LZH. На данный момент ситуация значительно изменилась. Первое место среди форматов архиваторов занимает ZIP, отвоевав его у ARJ, который отошел теперь на задний план, на втором месте RAR и со значительным отрывом следуют ACE, ARJ и другие менее популярные форматы.
Таким образом, в нашем обзоре нас интересуют в первую очередь архиваторы самых распространенных форматов:
ZIP — формат был разработан PKWARE.
RAR — формат был разработан Евгением Рошалем, автором одноименного архиватора и благодаря удобному интерфейсу архиватора одновременно с хорошим сжатием завоевал популярность.
2.4 Основные виды программ-архиваторов
Наиболее известные программы-архиваторы для MS-DOS: ARJ (разработчик — Robert K. Jung), pkzip (компания PKWARE Inc.), lha (Haruyasu Yoshizaki), zoo (Rahul Dhesi).
Безусловным лидером во всем мире за последние 5 лет стал архиватор RAR. В настоящее время RAR активно вытесняет ZIP как основную утилиту сжатия FTP архивов в сети INTERNET. RAR я является единственной всемирно используемой программой, созданной русским программистом (за исключением TETRIS).
Все архиваторы отличаются используемыми алгоритмами сжатия, форматами архивных файлов, скоростью работы и т.д.
В настоящее время применяется несколько десятков программ-архиваторов, которые отличаются перечнем функций и параметрами работы, однако лучшие из них имеют примерно одинаковые характеристики. Из числа наиболее популярных программ можно выделить:
ARJ, РКРАК, LHA, ICE, HYPER, ZIP, РАК, ZOO, EXPAND, разработанные за рубежом, а также AIN и RAR, разработанные в России. Обычно упаковка и распаковка файлов выполняются одной и той же программой, но в некоторых случаях это осуществляется разными программами, например, программа PKZIP производит упаковку файлов, a PKUNZIP — распаковку файлов.
Многие программы-архиваторы производят распаковку файлов, выгружая их на диск, но имеются и такие, которые предназначены для создания упакованного исполняемого модуля (программы).
В результате такой упаковки создается программный файл с теми же именем и расширением, который при загрузке в оперативную память самораспаковывается и сразу запускается. Вместе с тем возможно и обратное преобразование программного файла в распакованный формат. К числу таких архиваторов относятся программы PKLITE, LZEXE, UNP.
Программа EXPAND, входящая в состав утилит операционной системы MS DOS и оболочки Windows, применяется для распаковки файлов программных продуктов, поставляемых фирмой Microsoft.
Программы-архиваторы RAR и AIN, кроме обычного режима сжатия, имеют режим solid, в котором создаются архивы с повышенной степенью сжатия и особой структурой организации. В таких архивах все файлы сжимаются как один поток данных, т.е. областью поиска повторяющихся последовательностей символов является вся совокупность файлов, загруженных в архив, и поэтому распаковка каждого файла, если он не первый, связана с обработкой других. Архивы такого типа предпочтительнее использовать для архивирования большого числа однотипных файлов,
2.4.1 Программы-архиваторы для MS-DOS
2.4.1.1 Программа- архиватор ARJ
Достоинства:, Недостатки:
Программа ARJ позволяет:
-
создавать архивные файлы из отдельных или всех файлов текущего каталога и его подкаталогов, загружая в один архив до 32000 файлов;
-
добавлять и заменять файлы в архиве;
-
извлекать и удалять файлы из архива;
-
просматривать содержимое архива;
-
создавать многотомный архив;
-
защищать каждый из помещенных в архив файлов 32-битовым циклическим кодом, тестировать архив, проверяя сохранность в нем информации;
-
получать помощь по работе на 3 международных языках;