В процессе выполнения данной работы была спроектирована база данных для библиотеки и разработана программа для её удобного использования.
Разработка базы данных осуществлялась специально по заказу библиотеки на одном из факультетов университета, где и планируется ее дальнейшее использование.
Целью создания базы данных является хранение сведений о статьях из периодических изданий для дальнейшего их оперативного нахождения.
Разработанное приложение в наглядном виде отображает данные из базы, и обеспечивает удобную работу с ними. При его разработке основное внимание было акцентировано на следующих ключевых моментах:
- удобный пользовательский интерфейс;
- полнотекстовый поиск по различным критериям;
- автоматизированный ввод новых статей.
Созданная база данных и приложение разработаны на основе технологий, разрешающих их свободное использование.
Разработанное решение позволяет без дополнительных экономических затрат организовать хранение и использование существующей информации, а также автоматизировать действия по созданию новых данных.
В первой части данной работы проводится анализ предметной области и выявление требований к разрабатываемому приложению и базе данных.
Во второй части обосновывается выбор используемой базы данных, описываются стадии проектирования и используемые технологии.
В третьей части показана реализация наиболее интересных моментов в разработанном приложении: запросов к базе данных и процесса распознавания фрагмента изображения.
В четвертой части демонстрируются пользовательский интерфейс и принципы работы с программой.
1. Анализ предметной области
Предметная область представляет собой реальную библиотеку на одном из факультетов университета.
Библиотека выписывает периодические издания (на профессиональном языке — периодика).
Список журналов обычно формируется на основании перечней литературы, которые предоставляют в библиотеку заведующие кафедр факультета.
Каждый полученный журнал библиотека регистрирует и размещает его в соответствующем месте. Также для облегчения поиска нужной информации проводится некоторая обработка содержимого. Каждая статья из журнала заносится в базу данных. Затем в случае необходимости поиска информации осуществляется отбор данных согласно текстовому запросу из базы и вывод найденных статей на экран.
Существующая база данных использовалась на протяжении 10 лет,и в ней накопился большой объем информации по имеющимся в библиотечном фонде журналам. Однако эта база имеет неудобный пользовательский интерфейс и ограниченные возможности поиска информации. Кроме того, со временем в библиотеке появился сканер, и возникла идея о возможности облегчить монотонный труд библиотекаря, заносившего данные по каждой статье в базу.
Теория проектирования удаленных баз данных
... с одноранговой сетью. В подавляющем большинстве случаев локальная сеть используется для коллективного доступа к базам данных. 1.1.2 Основные тенденции развития средств удаленного управления Общие положения. Удаленный доступ ... ней доступ. При удаленном доступе администратор может ограничить пользователя в загрузке информации на свой домашний ПК. Недостатки удаленного управления Программы удаленного ...
Конечно, идея автоматизации деятельности библиотеки не нова и на рынке программных средств существует несколько готовых решений для ее осуществления. Например, такая известная система автоматизации библиотек как ИРБИС. Однако продукт является проприетарным, и у библиотеки нет возможности его приобретения.
В связи с этим было принято решение создать новую базу данных, на основе существующей, и при этом учесть изменившиеся со временем требования. Соответственно, для работы с базой необходимо создать приложение, основными преимуществами которого перед существующим решением являлись:
- более удобный пользовательский интерфейс;
- полнотекстовый поиск по различным критериям;
- автоматизированный ввод новых статей.
В процессе анализа возможных способов автоматизации было принято решение реализовать следующий алгоритм:
- Сканирование содержания журнала и сохранение его в виде изображения на компьютере;
- Открытие изображения на компьютере в разработанной программе;
- Выделение на изображении прямоугольных областей, содержащих необходимую информацию;
- Распознавание в каждом выделенном фрагменте текстовых символов и перенос их в соответствующие текстовые поля;
- Сохранение занесенной информации в базу данных.
Предложенный алгоритм повторяется для каждого полученного библиотекой журнала. Помимо этого, так как в журнале обычно печатается по несколько статей, этапы 3, 4 и 5 повторяются для каждой из них.
Также следует отметить, что использоваться разработанная программа и база данных к ней будут на компьютере с бюджетной конфигурацией, поэтому при разработке следует обратить внимание на минимальное использование ресурсов компьютера, и в первую очередь на минимальное потребление оперативной памяти. Работать с программой будет преимущественно один обученный сотрудник библиотеки, хотя в дальнейшем возможна перспектива расширения на несколько рабочих мест.
2. Проектирование базы данных
1 Выбор СУБД
Файл-серверные СУБД
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается на каждом клиентском компьютере (рабочей станции).
Доступ СУБД к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на ЦП сервера. Недостатки: потенциально высокая загрузка локальной сети; затруднённость централизованного управления; затруднённость обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность. Применяются чаще всего в локальных приложениях, которые используют функции управления БД.
Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
Объектно-ориентированные базы данных. _Объектно-ориентированные_БД. ...
... объектно-ориентированных баз данных Преимущества объектно-ориентированных баз данных (ООБД) неоспоримы. Во-первых, существует возможность повторного использования объектов. СУБД ... базами данных. Некоторые из популярных DDBMS - это Oracle, SQL Server, MySQL, SQLite и IBM DB2. Реляционная база данных имеет два основных преимущества: Реляционные базы данных легки в освоении. Записи базы данных ...
На данный момент файл-серверная технология считается морально устаревшей, поэтому при выборе базы данных для библиотеки предпочтительней использовать другие, более современные технологии.
Клиент-серверные СУБД
Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно, в монопольном режиме. Все клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно. Недостаток клиент-серверных СУБД состоит в повышенных требованиях к серверу. Достоинства: потенциально более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность.
Примеры: Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL.
На сегодняшний день разработчики программного обеспечения используют в основном именно клиент-серверные СУБД. Помимо таких мощных коммерческих продуктов как Oracle, MS SQLServer или Interbase, существует много и других разнообразных по функциям и возможностям баз данных, в том числе и бесплатных. Однако все они в силу своей архитектуры весьма требовательны к аппаратным ресурсам, поскольку для их работы требуется отдельный работающий процесс, обычно потребляющий немалый объем памяти. Поэтому для проекта библиотеки этот вариант тоже не подходит.
Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети. Физически встраиваемая СУБД чаще всего реализована в виде подключаемой библиотеки. Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы.
Примеры: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Sav Zigzag, Microsoft SQL Server Compact.
Одной из встроенных СУБД, активно набирающей популярность в последнее время, является SQLite — компактная встраиваемая база данных.
SQLite
SQLite — легковесная встраиваемая реляционная база данных. SQLite является совершенно бесплатной для использования в любых проектах.
SQLite состоит из библиотеки, которая добавляется к разрабатываемой программе и таким образом становится её составной частью. Таким образом, в качестве протокола обмена используются вызовы функций библиотеки SQLite. Такой подход уменьшает накладные расходы, время отклика и упрощает программу. SQLite хранит всю базу данных (включая определения, таблицы, индексы и данные) в единственном стандартном файле на том компьютере, на котором исполняется программа. Простота реализации достигается за счёт того, что перед началом исполнения транзакции записи весь файл, хранящий базу данных, блокируется.
Несколько процессов или потоков могут одновременно без каких-либо проблем читать данные из одной базы. Запись в базу можно осуществить только в том случае, если никаких других запросов в данный момент не обслуживается; в противном случае попытка записи оканчивается неудачей, и в программу возвращается код ошибки. Другим вариантом развития событий является автоматическое повторение попыток записи в течение заданного интервала времени.
В комплекте поставки идёт также функциональная клиентская часть в виде исполняемого файла sqlite3, с помощью которого демонстрируется реализация функций основной библиотеки. Клиентская часть работает из командной строки, позволяет обращаться к файлу БД на основе типовых функций ОС.
На текущий момент максимальный размер файла базы данных составляет примерно 32 ТБ.
Сама библиотека SQLite написана на C; существует большое количество привязок к другим языкам программирования, в том числе C++, Java, C#, VB.NET, Python, Perl, PHP, Tcl, Ruby, Haskell, Scheme, Smalltalk, LuaиParser, а также ко многим другим.
Обоснование выбора SQLite
За 10 лет использования существующей базы данных, построенной на основе программного продукта MicrosoftAccess, в ней накопилась информация о 16500 статьях. При этом объем потребляемого дискового пространства составил порядка 15 мегабайт. Та же информация в SQLite заняла всего 4 мегабайта. Так же по результатам тестирования SQLite обладает лучшей производительностью и меньшим потреблением оперативной памяти.
Основной платформой разработки приложений для Windows является .NET. Поэтому важным моментом является наличие готового качественного ADO.NET провайдера для работы с SQLite. Данный провайдер так же позволяет задействовать все дополнительные возможности последних версий .NET, такие как LINQ, EntityFramework.
2 Инфологическое проектирование
Концептуальное (инфологическое) проектирование — построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных.
Для построения инфологической модели необходимо на основании анализа предметной области определить основные сущности, их атрибуты и выявить связи между ними.
Для разрабатываемой базы данных характерны
Название(Title)
Год (Year)
Журнал (Journal)
Статья (Article)
Описание связей между сущностями представлено в таблице 2.1.
|
№ п/п |
Сущность 1 |
Сущность 2 |
Тип связи |
Описание |
|
1 |
Title |
Journal |
1:M |
У каждого журнала в списке (Title) может быть несколько конкретных номеров (Journal) |
|
2 |
Year |
Journal |
1:M |
Каждый поступивший номер журнал (Journal) может быть только за определенный год (Year) |
|
3 |
Author |
Article |
1:M |
У конкретного автора (Author) может быть несколько написанных им статей (Article) |
|
4 |
Journal |
Article |
1:M |
В одном номере журнала (Journal) публикуются несколько статей (Article) |
Таблица 2.1. Описание связей между сущностями.
Определение атрибутов сущностей:
- Автор (Author): номер автора (id_author), автор или коллектив авторов (author);
- Название (Title): номер журнала (id_title), его название (title);
- Год (Year): номергода (id_year), год (year);
- Журнал (Journal): номер поступившего журнала (id_journal), какое издание (id_title), за какой год (id_year) и за какой месяц (issue);
- Статья (Article): номер статьи (id_article), в каком журнале (id_journal), кто автор (id_author), название статьи (title), ключевые слова (keywords), на какой странице (page) и дата поступления (date).
Графическое изображение концептуальной модели обычно называется ER-диаграммой, а правила графического обозначения ER-диаграмм — нотацией.
На рисунке 2.1 изображена ER-диаграмма в нотации Баркера.
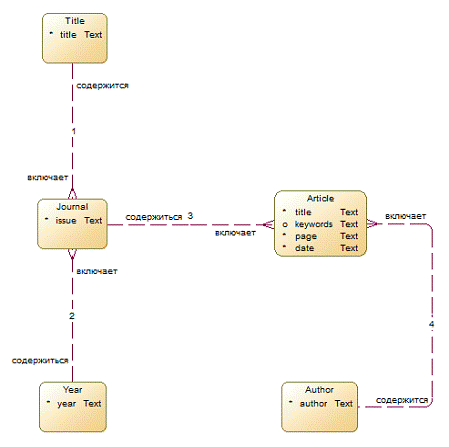
Рисунок 2.1. ER — диаграмма в нотации Баркера
3 Даталогическое проектирование
Логическое (даталогическое) проектирование — создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных даталогическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи.
На рисунке 2.2 представлена схема базы данных в нотации Баркера.
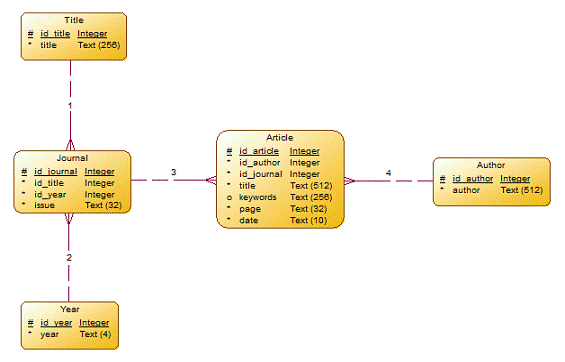
Рисунок 2.2. Схема базы данных в нотации Баркера
4 Физическое проектирование
Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т.п.
Листинг 2.1 содержит запрос для создания схемы базы данных.
CREATETABLE[Author]
[id_author]INTEGERPRIMARYKEYAUTOINCREMENTNOTNULL,
[author]NVARCHAR(512)NOTNULL
;
CREATETABLE[Title]
[id_title]INTEGERPRIMARYKEYAUTOINCREMENTNOTNULL,
[title]NVARCHAR(256)NOTNULL
;
CREATETABLE[Year]
[id_year]INTEGERPRIMARYKEYAUTOINCREMENTNOTNULL,
[year]NVARCHAR(4)NOTNULL
CREATETABLE[Journal]
[id_journal]INTEGERPRIMARYKEYAUTOINCREMENTNOTNULL,
[id_title]INTEGERNOTNULL,
[id_year]INTEGERNOTNULL,
[issue]NVARCHAR(32)NOTNULL,(id_title)REFERENCESTitle(id_title),(id_year)REFERENCESYear(id_year)
;
CREATETABLE[Article]
[id_article]INTEGERPRIMARYKEYAUTOINCREMENTNOTNULL,
[id_journal]INTEGERNOTNULL,
[id_author]INTEGERNOTNULL,
[title]NVARCHAR(512)NOTNULL,
[keywords]NVARCHAR(256)NULL,
[page]NVARCHAR(32)NOTNULL,
[date]NVARCHAR(10)NOTNULL,(id_author)REFERENCESAuthor(id_author),(id_journal)REFERENCESJournal(id_journal)
;
- Листинг 2.1. Запрос создания схемы базы данных
2.5 Используемые технологии
ADO.NET провайдер System.Data.SQLite для .NET
Для работы с SQLite в .NETсуществует готовый ADO.NET провайдер. Данный провайдер так же позволяет задействовать все дополнительные возможности последних версий .NET, такие как LINQ, EntityFramework.
Надо отдать должное разработчикам провайдера для SQLite, которые обеспечили поддержку почти всех доступных платформ. Все, что необходимо сделать — выбрать нужную версию сборки System.Data.SQLite.dll. Сама сборка скомпилирована в различных вариациях; в разрабатываемом приложении используется сборка System.Data.SQLite.dll, в которой уже содержится неуправляемый код движка SQLite.
Если используется среда разработки VisualStudio (в частности версия 2008), то так же пригодится SQLiteDesigner, который дает возможность использовать визуальные средства для работы с базами SQLite: построитель запросов (QueryBuilder), редактирование таблиц и ряд других возможностей.
В сборке используются классы SQLiteFactory, SQLiteConnection, SQLiteCommand, которые обеспечивают создание файла базы, подключение к источнику данных и выполнение SQL запросов. Эти классы реализуют поддержку интерфейсов ADO.NET посредством наследования базовых абстрактных классов ADO.NET. Вот некоторые из них:
publicsealedclassSQLiteFactory : DbProviderFactory, IServiceProvider: DbConnection, ICloneable
Так, класс SQLiteFactory реализует функционал DbProviderFactory, аSQLiteConnection — DbConnection. Классы DbProviderFactory и DbConnection являются частью стандартных абстрактных классов ADO.NET, интерфейсы которых обеспечивают унифицированный доступ к данным вне зависимости от используемой СУБД.
В целом провайдер для SQLite реализует весь функционал, который необходим для работы с базами как на связанном, так и несвязанном уровнях ADO.NET.
ADO.NET EntityFramework
ADO.NET EntityFramework(EF) — объектно-ориентированная технология доступа к данным от Microsoft.EntityFramework предоставляет возможность взаимодействия с реляционными базами данных через объектную модель, которая отображается непосредственно на бизнес-объекты приложения.
EntityFramework предоставляет возможность вместо традиционной трактовки данных, как коллекции строк и столбцов, оперировать коллекциями строго типизированных объектов, именуемых сущностями. Сущности — это концептуальная модель физической базы данных, которая отображается на предметную область. Формально эта модель называется моделью сущностных данных (EntityDataModel — EDM) . Модель EDM представляет собой набор классов клиентской стороны, которые отображаются на физическую базу данных. Сущностные классы можно реструктурировать для соответствия существующим потребностям, и исполняющая среда EF отобразит эти уникальные имена на корректную базу данных.
На рисунке 2.3 изображена сгенерированная в VisualStudio2010 модель сущностных классов для проектируемой базы данных.
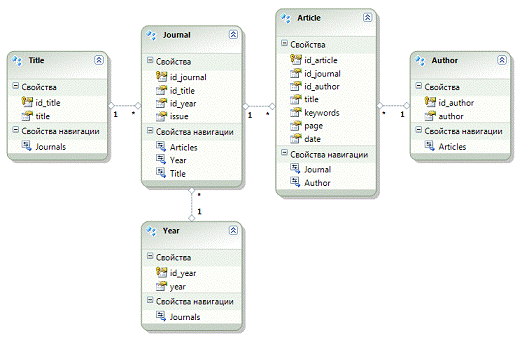
Рисунок 2.3. Модель сущностных классов для базы данных библиотеки
LINQ
LINQ (LanguageIntegratedQuery — язык интегрированных запросов) — технология Microsoft, предназначенная для поддержки запросов к данным для всех типов на уровне языка. Эти типы включают массивы и коллекции в памяти, базы данных, документы XML и многое другое.
LINQ позволяет использовать SQL-подобный синтаксис непосредственно в коде программы, написанной, например, на языке C#, используя некоторые новые особенности языка:
Не явно типизированные локальные переменные
Синтаксис инициализации объектов и коллекций
Лямбда-выражения
Расширяющиеся методы
Анонимные методы
Синтаксис выражений запросов
LINQ to Entities
LINQtoEntities — это интерфейсLINQ, используемый для обращения к базе данных. Он отделяет сущностную объектную модель данных от физической базы данных, вводя логическое отображение между ними. Так, например, схемы реляционных баз данных не всегда подходят для построения объектно-ориентированных приложений и в результате объектная модель приложения существенно отличается от логической модели данных. В этом случае используется LINQtoEntities, который использует модель EDM (EntityDataModel).
То есть, если нужно ослабить связь между сущностной объектной моделью данных и физической моделью данных, например, если сущностные объекты конструируются из нескольких таблиц или нужна большая гибкость в моделировании сущностных объектов предпочтительнее использовать LINQtoEntities.
3. Разработка приложения
Рассмотрим ключевые моменты разработанной программы.
3.1 Запросы к базе данных
Все запросы к базе данных разработанная программа содержит в отдельном классе Database.
Листинг 3.1 показывает поля, свойства и определения методов этого класса:
publicclassDatabase
{Database()
{= newDatabaseEntities();= newList<Item>();= newList<Search>();= false;
- }database;<Item>
- items;<Search>
- searches;<Search>
- Searches
{{ return searches; }{ searches = value; }
};
- {{ returnsearchInResults;
- }{ searchInResults = value;
- }
}(ItemaddItem)
{
}(ItemeditItem)
{
}(ItemdeleteItem)
{
}<Item>SearchItems()
{
}(stringsearchString)
{!= string.Empty;
- }<Item>GetItems()
{items;
- }<Item>SelectItems()
{
{
}<Item>SelectArticleAndKeywords(stringsearchString)
{
}<Item>SelectAuthorAndArticle(stringsearchString)
{
}<Item>SelectJournal(stringsearchString)
{
}<Item>SelectAll(stringsearchString)
{
}<string>SelectAllJournals()
{
}<string>SelectAllYears()
{
}()
{
}()
{
}
}
Листинг 3.1. Класс Database, инкапсулирующий работу с базой данных
Класс Database определяет поле database типа DatabaseEntities. Этот тип является классом, предоставляющим функциональность EntityFramework — отображение таблиц физической базы данных на набор классов, содержащих методы для манипулирования данными.
Листинги 3.2, 3.3 и 3.4 демонстрируют добавление в базу новой статьи и изменение или удаление существующей.
publicboolAddItem(ItemaddItem)
{success = false;
- {= (from t indatabase.Titles.title == addItem.Journalt).SingleOrDefault();= (from a indatabase.Authors.author == addItem.Authora).SingleOrDefault();= (from y indatabase.Years.year == addItem.Yeary).SingleOrDefault();= (from j indatabase.Journals
(j.Title.title == addItem.Journal&&.Year.year == addItem.Year&&.issue == addItem.Issue)j).SingleOrDefault();article = newArticle
{
Journal = (hasJournal == null ?
{
Title = (hasTitle == null ?newTitle { title = addItem.Journal } : hasTitle),
Year = (hasYear == null ?newYear { year = addItem.Year } : hasYear),= addItem.Issue
}
: hasJournal),
Author = (hasAuthor == null ?newAuthor { author = addItem.Author } : hasAuthor),= addItem.Article,= addItem.Keywords,= addItem.Page,= addItem.Date
};.Articles.AddObject(article);.SaveChanges();= true;
}(Exception ex)
{.Show(ex.Message);= false;
}
returnsuccess;
}
Листинг 3.2. Добавление новой статьи в базу
publicboolEditItem(ItemeditItem)
{success = false;
- {article = (from a indatabase.Articles.id_article == editItem.Ida).Single();= (from t indatabase.Titles.title == editItem.Journalt).SingleOrDefault();= (from a indatabase.Authors.author == editItem.Authora).SingleOrDefault();= (from y indatabase.Years.year == editItem.Yeary).SingleOrDefault();= (from j indatabase.Journals
(j.Title.title == editItem.Journal&&.Year.year == editItem.Year&&.issue == editItem.Issue)j).SingleOrDefault();.Journal = (hasJournal == null ?
{
Title = (hasTitle == null ?newTitle { title = editItem.Journal } : hasTitle),
Year = (hasYear == null ?newYear { year = editItem.Year } : hasYear),= editItem.Issue
}
: hasJournal);.Author = (hasAuthor == null ?newAuthor { author = editItem.Author } : hasAuthor);.title = editItem.Article;.keywords = editItem.Keywords;.page = editItem.Page;.date = editItem.Date;.SaveChanges();
- = true;
}(Exception ex)
{.Show(ex.Message);= false;
}
returnsuccess;
}
Листинг 3.3. Изменение существующей статьи в базе
publicboolDeleteItem(ItemdeleteItem)
{success = false;
- {article = (from a indatabase.Articles.id_article == deleteItem.Ida).Single();.DeleteObject(article);.SaveChanges();= true;
}(Exception ex)
{.Show(ex.Message);= false;
}
returnsuccess;
}
Листинг 3.4. Удаление устаревшей статьи из базы
Листинг 3.5 содержит метод SearchItem(), который вызывается внешним кодом для получения нужной информации исходя из выбранной категории поиска и сформулированного запроса.
publicList<Item>SearchItems()
{(!searchInResults)
{= SelectItems();
- {(IsSearch(search.String))
{(search.Type)
{.All:= SelectAll(search.String);;.Journal:= SelectJournal(search.String);;.Author:= SelectAuthorAndArticle(search.String);;.Article:= SelectAuthorAndArticle(search.String);;.Keywords:= SelectArticleAndKeywords(search.String);;.Date:= SelectDate(search.String);;:;
}
}
}items;
}
Листинг 3.5. Поиск необходимой информации
Листинги 3.6 — 3.9 содержат различные используемые в программе запросы к базе данных.
privateList<Item>SelectItems()
{query = from a indatabase.Articles
{
Id = a.id_article,
Journal = a.Journal.Title.title,
Year = a.Journal.Year.year,
Issue = a.Journal.issue,
Author = a.Author.author,
Article = a.title,
Keywords = a.keywords,
Page = a.page,
Date = a.date
};
- returnquery.ToList();
}
Листинг 3.6. Извлечение всех статей из базы
privateList<Item>SelectAll(stringsearchString)
{= newRegex(searchString, RegexOptions.IgnoreCase);query = from i in items
(regex.Match(i.Journal).Success ||.Match(i.Author).Success ||.Match(i.Article).Success ||.Match(i.Keywords).Success)i;.ToList();
}
Листинг 3.7. Поиск информации по категориям «по журналу», «по автору», «по статье» и «по ключевым словам».
publicList<string>SelectAllJournals()
{<string> journals = newList<string>();= (from t indatabase.Titles.title).ToList<string>();;
}
Листинг 3.8. Получение списка зарегистрированных журналов
publicstringSelectLastYear()
{<string>stringYears = SelectAllYears();<int>intYears = newList<int>();(string y instringYears)
{.Add(int.Parse(y));
- }= intYears.Max();year = maxYear.ToString();;
}
Листинг 3.9. Поиск года издания самого свежего журнала
2 Распознавание изображений
Puma.NET
CuneiForm — это свободно распространяемая открытая система оптического распознавания текстов российской компании CognitiveTechnologies.
Puma.NET — это обертка для движка CuneiFrom, которая делает его удобным для использования в приложениях на .NET 2.0 и выше с функциональностью OCR. Хорошие результаты распознавания могут быть достигнуты несколькими строками кода.
Возможности OCR:
- Распознавание множества печатаемых шрифтов;
- Поддержка 27 языков, среди которых есть и русский;
- Проверка правописания;
- Автоматическое определение шрифтов (курсив, подчеркнутый);
- Сохранение структуры документа (абзацы, изображения, таблицы);
- Улучшенное распознавание текста, расположенного под углом;
- Входные форматы изображений: BMP, GIF, JPG, PNG и TIFF;
- Выходные форматы: TXT, RTF, HTML.
Использование Puma.NET
Среда распознавания Puma.NET состоит из 4 компонентов:
- Puma.Net.dll — библиотека, которая содержит классы, используемые в приложении для получения возможности распознавания;
- Бинарные файлы CuneiForm (PumaCOM, библиотеки, словари и т.д.) — движок распознавания от CognitiveTechnologies;
- puma.interop.dll — сборка для обеспечения взаимодействия между Puma.Net.dll и PumaCOMServer;
- dibapi.dll — библиотекаWin32,содержащая необходимые для работы со структурами данных функции, которые используют PumaCOM и puma.interop.dll.
Чтобы воспользоваться возможностями Puma.Net необходимо добавить в проект ссылку на Puma.Net.dll и скопировать файлы puma.interop.dll и dibapi.dll в рабочую папку приложения.
Разработанная программа содержит всю функциональность распознавания в отдельном классе Recognizer (листинг 3.10).
Метод Recognize создает объект класса PumaPage, которому в качестве параметра передается изображение. Затем у объекта вызывается метод RecognizeToString, который выполняет всю работу по распознаванию. Возвращенная строка содержит набор символов, найденных на изображении.
publicclassRecognizer
{
privatePumaLanguage language = PumaLanguage.Russian;
- privateboolautoRotateImage = true;Recognize(Bitmap image)
{recognize = string.Empty;(PumaPagepumaPage = newPumaPage(image))
{.Language = language;.AutoRotateImage = autoRotateImage;(int i = 0; i < 5; i++)
{
{= pumaPage.RecognizeToString();;
}(RecognitionEngineException ex)
}(Exception ex)
{(«Неудаетсяраспознать»);
}
}
}
returnrecognize;
}
}
Листинг 3.10. Класс Recognizer, выполняющий работу по распознаванию.
Работа приложения
Рассмотрим работу приложения на примере поиска статей по заданным условиям, а также операций с данными — добавления в базу, редактирования и удаления.
После запуска приложения пользователю отображается основное рабочее окно приложения (рисунок 4.1).
Интерфейс программы предполагает работу в двух режимах: простом и расширенном. Простой режим предназначен для поиска статей по различным критериям: по журналу, по автору, по статье, по ключевым словам, по дате поступления. Помимо этого, присутствует возможность поиска в результатах предыдущего запроса, что, несомненно, весьма удобно. Расширенный режим добавляет несколько кнопок, которые позволяют создавать новые, изменять существующие и удалять устаревшие статьи (рисунок 4.2).
Причиной разделения на два режима послужил тот факт, что чаще всего пользователь просто ищет нужные данные, тогда как добавлять новые нужно редко, но по многу.
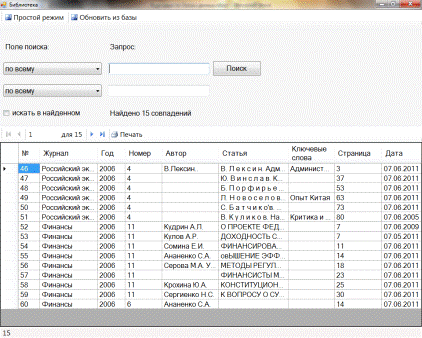
Рисунок 4.1. Простой режим
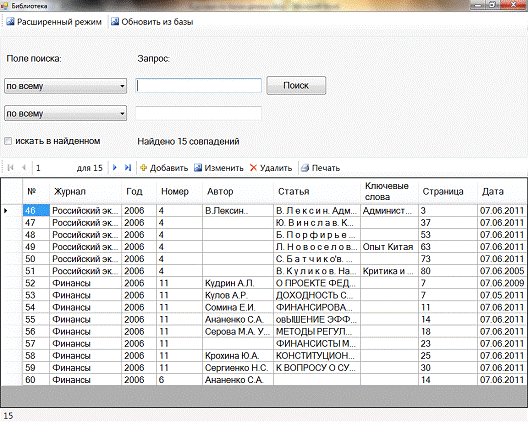
Рисунок 4.2. Расширенный режим
Поиск нужной информации осуществляется по нажатию кнопки «Поиск» (рисунок 4.3).
При этом если в текстовых окнах введен запрос, то в результате данные из базы фильтруются в соответствии с запросом. Если в обоих текстовых окнах содержится выражение запроса, то будут отображены только те статьи, в которых одновременно выполняются оба запроса. В зависимости от выбранной категории поиск осуществляется по разным столбцам. Если в поле поиска задано значение «по всему», то в результате будут отображены только те статьи, в которых строка запроса будет содержаться в одном из столбцов «Журнал», «Автор», «Статья» или «Ключевые слова»;значение «по журналу» — в столбце «Журнал»; значение «по автору» — в столбцах «Автор» и «Статья»; значение «по статье» — также в столбцах «Автор» и «Статья»; «по ключевым словам» — в «Статья» и «Ключевые слова» и «по дате» — в «Дата».
Найденные данные отображаются в таблице.
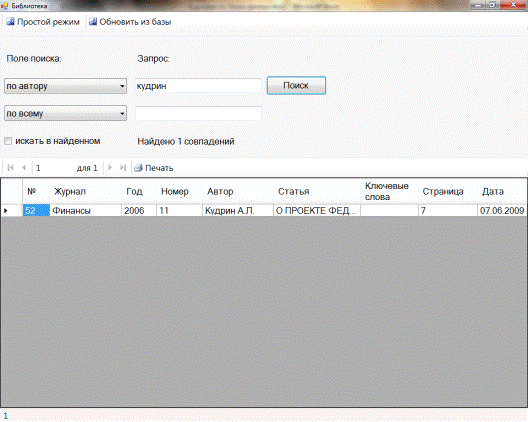
Рисунок 4.3. Поиск по запросу
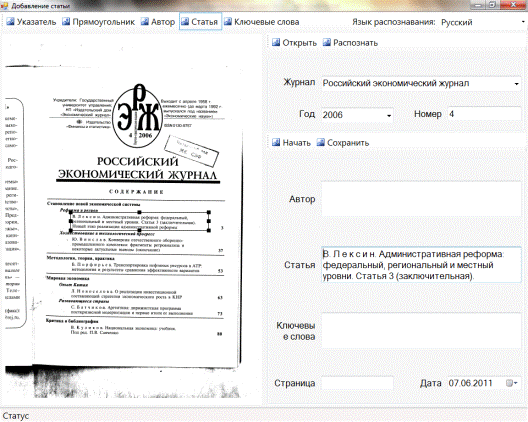
Для добавления в базу новых статей необходимо нажать кнопку «Добавить». При этом откроется окно, разделенное на две части (рисунок 4.4).
В левой части отображается загруженное изображение, на котором с помощью одного из инструментов можно выделить часть изображения, содержащую нужные символы. Выделенный фрагмент можно распознать в одно из тектовых полей в правой части. Программа предусматривает несколько сценариев выполнения этих действий:
Можно активировать один из инструментов «Автор», «Статья» или «Ключевые слова» щелчком левой кнопкой мыши, затем выделить необходимый фрагмент, и нажать кнопку «Распознать». При этом распознанный текст поместится в соответствующее выбранному инструменту текстовое поле.
Если снова выбрать один из инструментов «Автор», «Статья» или «Ключевые слова», выделить соответствующий фрагмент, то распознать текст можно будет повторно нажав на один из этих инструментов. При этом во второй раз не обязательно нажимать на тот же инструмент, что и в первый:текстовое поле, куда заносится распознанная строка, определяется по последнему нажатому инструменту.
Также можно активировать инструмент «Прямоугольник», выделить фрагмент, и нажать на один из инструментов «Автор», «Статья» или «Ключевые слова».
Каждый из инструментов имеет соответствующую горячую клавишу: «Указатель» — F1, «Прямоугольник» — F2, «Автор» — F3, «Статья» — F4 и «Ключевые слова» — F5.
Для успешного внесения статьи в базу необходимо заполнить поля о текущем журнале — «Журнал», «Год», «Номер» и некоторую информацию о добавляемой статье: любое из полей «Автор» или «Статья», поля «Страница» и «Дата». Занести результат в базу можно нажав кнопку «Сохранить».